【论文精读】Attention is all you need
1. Abstract
看一篇文章,我们先看摘要和结论。
先看原文:
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 Englishto-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
详细解释
- 背景介绍:
- 主流*(截止文章发表时的 2017 年)的序列转录模型(意思是 Input 是一个序列,Output 也是一个序列,典型的场景就是翻译)*都是基于复杂循环或者卷积神经网络,它们都包含编码器和解码器。
- 最好的模型在编码器和解码器中还引入了注意力机制
- 本文做了什么工作:
- 提出了一个新的简单的架构,叫 Transformer ,它是纯基于注意力机制,摒弃了循环神经网络和卷积神经网络
- 测试了两个机器翻译任务,取得的成绩:
- 更好的翻译效果——英德翻译取得 28.4 BLEU*(BLEU 是机器翻译领域的一个计量单位,反正知道这个数字不低就行)*的分数,比最好的结果高了两个 BLEU
- 更好的并行计算能力
- 更低的训练成本——英法翻译任务上,做到了单模型效果最好的同时,只在 8 个 GPU 上训练了 3.5 天
- 展望
- 这个架构可以泛化到别的任务上
批注
这个摘要可以一句话概括为:“我们用了一个新的训练方法让机器翻译的翻译质量提升了”
这篇广为流传的经典文章,最开始其实只是聚焦在「机器翻译」这个很小的场景下,用一种新方法提升了机器翻译的效果。没有什么 AGI 的宏大故事,就是一个很垂的领域,很小的场景。这几个研究员在当时可能也预料不到 Transformer 这么大的潜力吧。
来自 Google 的几只蝴蝶扇动了一下翅膀,几年后在全球掀起一场至今看不见尽头的风暴。
2. Conclusion
看完摘要下一步就是直接看结论——先把握整体,再看细节。
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
The code we used to train and evaluate our models is available at https://github.com/ tensorflow/tensor2tensor.
详细解释
- 这是在序列转录任务中,第一个仅仅使用注意力机制的模型,把过往的所有循环层,全部替换成了多头自注意力 (multi-header self-attention)
- 在机器翻译任务中,Transformer 可以训练得比其他任务都快很多,且结果质量也更好
- 作者对于这种纯基于注意力机制的模型感到很激动,认为可以用在文本以外的别的任务上,包括图片、语音、视频*(后续其他人的工作,证明了作者这个预测是对的)*
- 代码库在 https://github.com/ tensorflow/tensor2tensor.
3. Intro
对摘要的扩充
- 当时时序模型中最常用的还是 RNN,包括 LSTM 和 GRNN。主流的工作都在语言模型和编/解码器的架构上。
- RNN 的计算方式是,从左往右一步步递归计算这个序列的下一个词,第 t 个词的隐藏状态 ht 由这两个参数决定:ht-1 和第 t 个词本身。简单来说就是 RNN 在把之前的所有信息放到一个隐藏状态里,以此计算下一个词的隐藏状态并预测
- RNN 的问题:
- 他是一步一步递归计算的,无法并行,计算性能很低。
- 时序信息是一步一步累计的,很早期的信息会像滑动窗口那样很容易丢掉,如果不想丢失信息的话,对内存要求又会极高
- 上述问题有很多改进方案,但这些问题依然存在。
- RNN 的问题:
- Attention 的应用:在这篇文章之前,编解码器已经在成功应用 Attention 机制了,它与 RNN 一起使用,可以更好地将编码器的信息传递给解码器
- Transformer:完全摒弃了 RNN,完全使用 Attention,可以做到很高的并行度
4. Background
讲了一下相关的前人工作以及这篇文章与前人这些工作的联系、区别。整理一下大概意思:
- 用到 multi-head 去实现多输出通道(似乎是可以识别不一样的模式?)的效果。这是一个 RNN 中一个比较好的方式,用纯注意力机制后,可以通过 multi-head 去模拟这个效果。
- 用到了自注意力机制。前人提出过,不是这篇论文创新,这里提一嘴然后引用一下。
- 这是第一个纯自注意力机制的模型
5. 模型架构
太细节的看不懂,从整体理解一下:
- 编/解码器的架构:
- 编码器:将原始的输入变成机器学习可以理解的向量数据。
- 解码器:拿到编码器的输出,生成一个序列。
- 机制上的区别:
- 编码器是一次性从整个句子的角度生成的数据(比如翻译任务中,编码器会一次性给出整个句子的翻译),但是解码器需要通过自回归的方式(把输出作为下一个 token 的输入)一个词一个词地解码
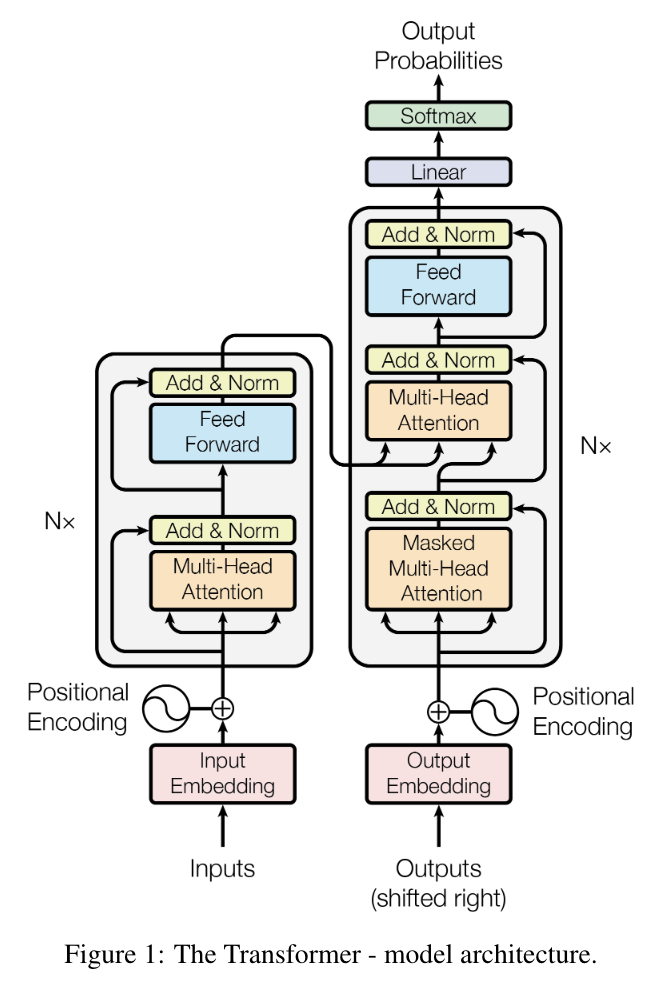
架构图
6. 模型+实验
这一块基本都是模型训练过程中的细节设计与实验步骤。由于自己没有复现一个 Transformer 的需求,略过。
7. 评价
-
NLP 领域的贡献
- Transform 最初提出时是应用在机器翻译任务上。后来大家发现这个架构不仅能用在机器翻译上,而是能在几乎所有 NLP 任务中都显著提升模型性能,曾经的 NLP 需要做大量的文本预处理并基于不同任务专门设计不同的模型架构,而 Transform 给后续的研究者提供了一个几乎通用、必学的统一架构,同时也让 pre-train 变得更加简单。
-
横向贡献
- 再往后,大家发现这个架构不仅仅在 NLP 领域,而是在图像、音频、视频上都适用。曾经是不同领域有不同架构,比如 CV 用 CNN,NLP 领域用 RNN,其他领域都有各自的不同架构,但 Transform 之后,大一统了各个领域的模型架构。
- 进一步地,由于 Transform 的通用性,让各个领域研究者使用了相同的研究语言,从而任何一个领域取得的突破,都可以很快地在别的领域得到使用、迁移。极大缩短了一项新技术在其他领域被应用的时间。
- 给了研究者一个鼓励:原来还有新的架构是可以打败统治了多年的 CNN/RNN 的。这种对固有认知的打破,也许会促生出更多有意思的研究。
-
研究问题——我们对 Attention 的理解依然是不够的
- 虽然标题叫「Attention is all you need」,但实际上它只是这个模型的一部分,后续的 MLP、残差连接等都是不可缺少的。并不是只靠 Attention 就能解决一切问题。
- 注意力的代价:Attention 根本不会对具体数据进行建模,而是用一种更广泛/一般化的方式处理信息,这会导致模型对训练数据中的信息抓取的能力变差,以至于必须要更多的数据、更大的模型,才能获取较好的效果